Analysis
Contents
First Movement (Allegro)
Form: Sonata Form. Bb Major.
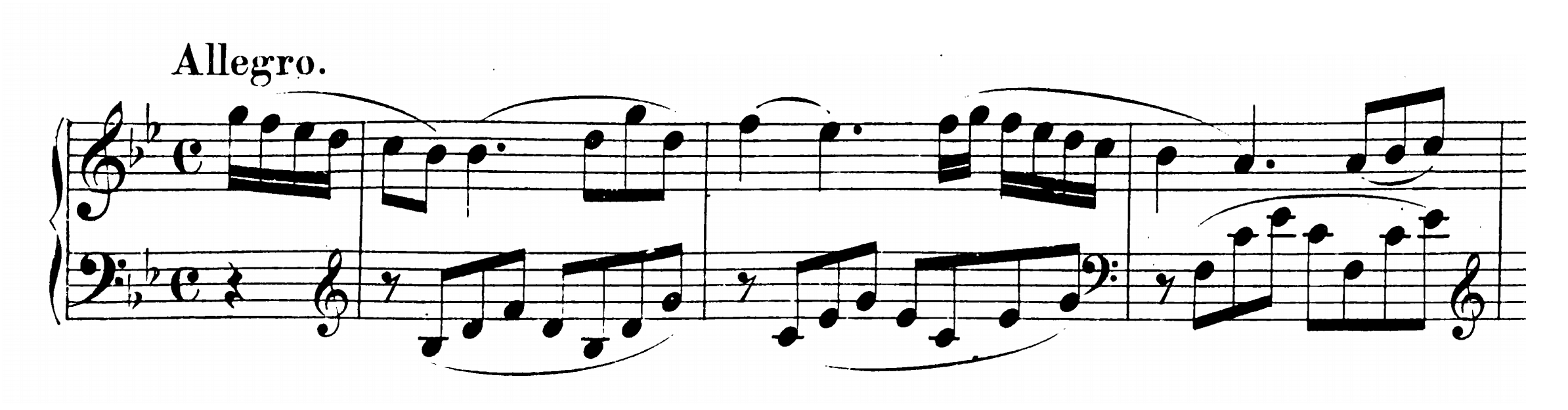
EXPOSITION:
Bars 1-10: First Subject in Tonic. The first subject is an eight-bar sentence prolonged to ten bars by repetition of the third two-bar section. The perfect cadence at the end of the first phrase (Bar 4) should be compared with that at the end of the sentence. It is a striking instance of how greatly the effect of the finality of the perfect cadence depends upon the twofold circumstance, viz.: (1) as to which note of the tonic chord is sounded in the highest part, and (2) as to whether or not this chord falls on a strong accent in the bar. In Bar 4, the pause given by the cadence may be said to be one of expectancy – the mind awaits something further which, instinctively, it feels must follow – and only in the second case is the effect produced one of complete rest.

Bars 10-22: Transition. The transition is founded principally on the opening figure of the first subject, with a repetition of which it commences. A variation of this figure – further slightly modified at each repetition – is heard three times in as many bars (Bars 14-17) and, with its first four notes augmented, twice in Bars 19-22. The passage modulates in the second bar to F major, in which key it ends on a half-cadence.
Bars 23-59: Second Subject in F major (Dominant). The first section of the second subject (Bars 23-38) is a sixteen-bar sentence in four-bar rhythm. The first half of the sentence ends on a half-cadence in F major, Bar 30, after which the third phrase repeats the contents of the first, with slight variations, the fourth phrase altering so as to lead to the final perfect cadence. The second section (Bars 39-50) is an eight-bar sentence prolonged to twelve by cadential repetition of the whole of the after-phrase. The inversion of the parts at the commencement of the cadential repetition should be noted. The third section (Bars 50-59) is a sentence of nine bars. It consists of a four-bar phase ending on a perfect cadence, which phrase is then repeated, being extended, the second time, to five bars. It should be noted that this lengthening, though not caused by doubling the value of each note (i.e. augmentation) is, however, caused by a double the length of each of the two chords in Bar 53.
Bars 59-63: Codetta. The special feature to notice in the short codetta is that its opening figure (repeated in Bar 61) is the same augmented figure, taken by inverse movement, which we have already met in Bars 19-21.
Double bar and repeat.
DEVELOPMENT:
Bars 63-93: The free fantasia starts with a sentence in the dominant founded on the opening figure of the first subject in combination with a three-note figure from the opening of the second section of the second subject. With the exception of a passing modulation to G minor, Bars 67-68, the sentence continues in F major until the very last chord where the sudden close on the chord of F minor, into which key the music now modulates, is very effective. The final cadence is a repetition of the one which occurs in the third section of the second subject, Bars 53-54. From this point the working-out refers to the semiquaver (sixteenth note) figures in Bars 35-36, as well as to the opening figure of the movement, the music modulating through C minor, and B flat, to G minor, in which key occurs a half-cadence, several times repeated, Bars 80-86. A passage written on the dominant in B flat follows, alternating between the two modes of the key, which serves as a connecting link leading to the recapitulation of the fist subject.
RECAPITULATION:
Bars 93-103: First Subject in Tonic (unaltered).
Bars 103-118: Transition (lengthened). The transition reappears lengthened from twelve to fifteen bars. The modification is in the first position, the last bars being a transposition of the corresponding portion of the original passage from the key of the dominant into that of the tonic.
Bars 119-161: Second Subject in Tonic (lengthened). With the exception of the second section, the second subject reappears in the key of the tonic but with very slight alteration. The second section (Bars 135-152) is, however, very much extended. Bars 143-146, excepting for the first group of quavers (eighth notes), form a descending, modulating sequence, passing through the keys of C minor, B flat major and G minor. The first chord, in Bar 147, is the first inversion of the chromatic supertonic seventh in B flat major, resolving on the second inversion of the tonic triad, here used as a passing 6/4; and the final chord, in Bar 146, is the chord of the Italian sixth on the flat submediant in the same key. The first section spans Bars 119-134 and the third section spans Bars 152-161.
Bars 161-165: Codetta. The movement closes with the original codetta transposed into the the key of the tonic.
Double bar and repeat.
Second Movement (Andante Cantabile)
Form: Sonata Form. Eb Major.

Though, generally speaking, it is unusual to find the slow movements in sonatas to be in sonata form, there are several examples to be fourd in those by Mozart for the pianoforte.
EXPOSITION:
Bars 1-8: First Subject in Tonic. The fist subject consists of one sentence, whose second phrase is an ornamented repetition of the first, modified also to ends on a perfect, instead of an a half, cadence, as in the fore-phrase.
Bars 8-13: Transition. The transition opens with an important five-note figure. In the second subject frequent allusions are made to the repeated notes with which it commences, and the free fantasia is founded almost entirely on it.
Bars 14-31: Second Subject in B flat major (Dominant). The second subject consists of two sentences (Bars 14-21 and 21-31), the second of which is prolonged by cadential repetitions. The fore-phrase of the first sentence subdivides into two two-bar sections; the after-phrase, which is founded on the first, and starts with transient modulation to the key of tonic, is not divisible into sections. In Bar 20, we find the figure from Bar 17 repeated with augmentation. The last three notes, in Bar 31, in E flat major, form a link leading to the repetition of the exposition, and to the free fantasia.
Double bar and repeat.
DEVELOPMENT:
Bars 32-50: The development is worked almost entirely on the opening figures of the transition. It starts in F minor, however, with an imitation – freely inverted – of the opening two bars of the first subject, the cadence in A flat major (Bars 42-43), being also founded on the final cadence in the same subject. From Bars 35-41, the five-note figure from the transition – with the second half of the figure augmented – is divided between the bass and the treble, the former ascending chromatically, and the passage modulating through C minor to A flat major. In Bar 43-44, the whole figure is transferred to the treble where, through F minor (Bars 44-45); D flat minor (Bars 46-47); to E flat major, on the dominant seventh in which key the section closes.
RECAPITULATION:
Bars 51-58: First Subject in Tonic (ornamented). As is very usual in the recapitulation in slow movements in sonata form, the first part reappears with florid ornamentation.
Bars 58-63: Transition (ornamented). As is very usual in the recapitulation in slow movements in sonata form, the first part reappears with florid ornamentation.
Bars 64-81: Second Subject in Tonic (varied). (64-71) (71-81)
Double bar and repeat.
Bars 81-82: One-bar Coda.
Third Movement (Allegretto Grazioso)
Form: Rondo-Sonata Form. Bb Major.
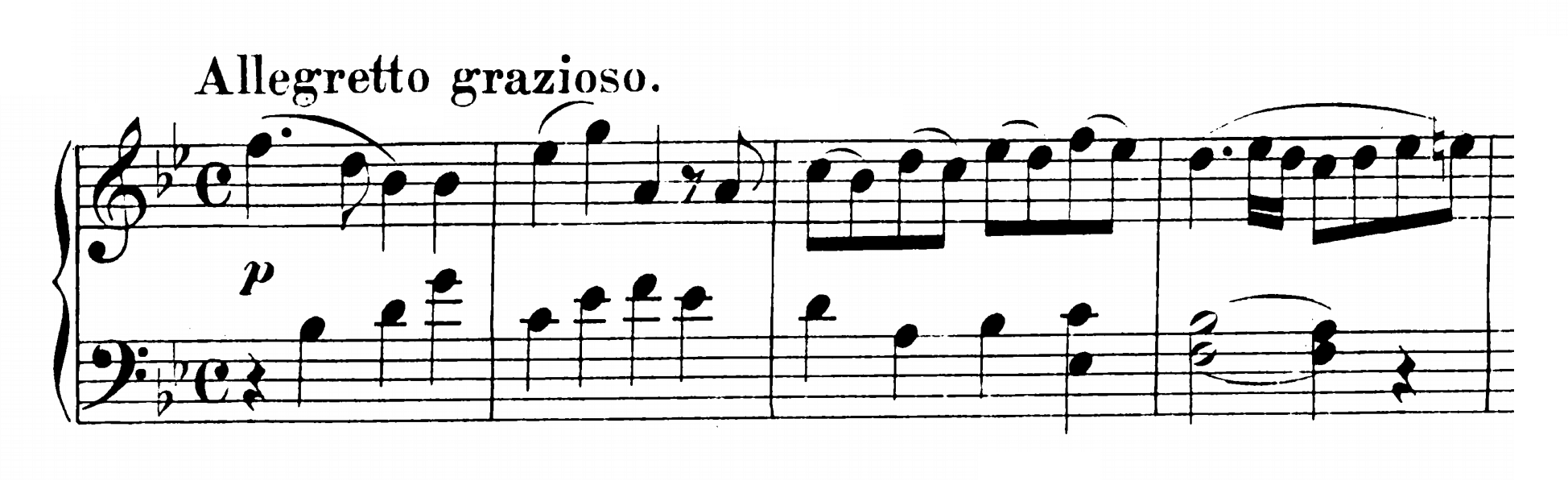
PART I (EXPOSITION):
Bars 1-16: Principle Subject in Tonic (first entry). The first subject consists of an eight-bar sentence ending with a perfect cadence in the tonic, after which the sentence is repeated with slight variations.
Bars 16-24: Transition. The transition commences with a new melody in the key of the tonic. Its second two-bar section is in free sequence with the first, and the following phrase also starts with a similar opening figure, commencing one degree higher. This modulates at once to F major (dominant), in which key the passage ends on a half-cadence, Bar 24.
Bars 24-36: Second Subject in F major (Dominant). The fore-phrase of the second subject consists entirely of repetitions of the opening motive, each time slightly varied. By a species of “augmentation” in the cadential repetition of the after-phrase, Bar 31 is converted into two bars – Bars 34-35 – the length of each of its two chords (though not of each individual note) being doubled.
Bars 36-40: Link. These few bars serve as a link between the second subject and the re-entry of the principle subject. It should be observed that the pedal-note is sustained both in the treble and bass during the first three bars, and also that, whilst this note starts as the tonic in the key of F major, it ends as the dominant (in the chord of the dominant seventh) in B flat major.
Bars 41-56: Principle Subject in Tonic (second entry).
PART II (EPISODE):
Bars 56-75: Transitional connecting passage. The transitional passage, commencing like the previous transition, afterwards modulates through G minor to E flat major, in which key, in Bar 76, the episode itself commences. The chords of the augmented sixth in Bar 63 should be noted, also the inversion of parts in Bar 63. Compare the figure in Bars 65 and 67, with Bar 5.
Bars 76-90: New melody. Episode.
Bars 91-111: Passage leading to Recapitulation. The full cadence, in Bar 89, is not sounded. We have, instead, an interrupted cadence and, two bars later, on a cadential repetition, a modulation to C minor, in which there is a sudden return to the opening phrase of the principle subject. This phrase reappears in the key of B flat – starting in the major, and changing into the minor mode – and prolonged, the music modulating transiently through G flat major, and E flat minor, back to the key of B flat minor. A repetition of the earlier link, here lengthened by two bars, follows and leads to the recapitulation of the principle subject. The chords of the augmented sixth in Bars 101 and 102 should be noted.
PART III (RECAPITULATION):
Bars 112-127: Principle Subject in Tonic (third entry).
Bars 127-148: Transition (much lengthened).
Bars 148-164: Second Subject in Tonic (lengthened). The second subject reappears in the key of the tonic slightly lengthened and varied.
Bars 164-171: Pedal, Tonic. This passage is founded on the link, Bars 36-40, and itself forms a connecting link between the recapitulation and the cadenza.
Bars 171-198: Cadenza in Tempo. The introduction of a cadenza into a pianoforte sonata is unusual. Since its main objective is to show off the powers and capabilities of the soloist, such a passage is rarely to be met with a work written entirely for a single executant. The cadenza is characteristic of a concerto, in which, for a long time, it formed an essential feature. It was usually marked to be interpolated, as in this instance, after the recapitulation, and after a pause on the chord of the 6/4, generally the chord Ic. This cadenza refers principally to the opening motive ( = two bars) of the principle subject, and to the figures from the link, Bars 36-40, which the passage is introduced in its entirety, Bars 179-183. It ends with brilliant scale passages which lead to the fourth entry of the principle subject. The pedals, the instances of “inversion of parts,” the melodic sequence over the pedal, Bars 186-188, and the harmonic sequence, Bars 189-193, should all be noted.
Bars 199-206: Principle Subject in Tonic (partial fourth entry only). This is a partial fourth entry of the principle subject which mergers into the Coda in Bar 206.
Bars 206-224: Coda. The Coda commences with a fragment of the second subject (repeated varied), and concludes with several bars reminiscent of the principle subject.





